기존의 Java IO는 다른 언어에 비해 매우 느리다는 이야기가 많이 있습니다. 내부적으로 어떻게 돌아가는지 대략적으로나마 파악한다면 그럴 수 밖에 없었다는 사실을 알게 되실겁니다. 하지만 jdk1.3부터는 Java IO의 한계를 보완한 Java NIO를 사용하여 I/O에서 속도 향상을 낼 수 있습니다. 그러나 NIO의 사용법은 기존 I/O와는 매우 달라 배우기가 생각만큼 쉽지는 않습니다. 이번 포스팅에서는 Java NIO에 대해 알아보고, 예제를 통해 FileHandling의 Performance를 향상시키는 간단한 예제를 다뤄 NIO에 쉽게 접할 수 있도록 하겠습니다. 생각보다 길어져서 포스팅을 세 개로 나누겠습니다.
- 기존 Java NIO의 단점과 NIO에서 어떻게 단점을 보완했는가? [[NIO] JAVA NIO의 ByteBuffer와 Channel로 File Handling에서 더 좋은 Perfermance내기!][related0]
- Java NIO의 Class들과 이들의 기본적인 사용법에 대해 알아보자. [[NIO] JAVA NIO의 ByteBuffer와 Channel 클래스 사용하기!][related1]
- 실제 FileHandling하는 간단한 예제와 실제로 Performance를 비교해보자. [[NIO] JAVA NIO와 일반 I/O로 구현한 파일 큐를 이용하여 파일 입출력 Performance 비교!][related2]
차근차근 포스팅하도록 하겠습니다. 제가 미흡한 점이 많습니다. 혹시 내용상 오류나 오탈자를 발견하신 분은 바로 댓글로 태클 걸어주시면 감사하겠습니다^^
1. 기존 JAVA IO 왜 느리다고 했을까?
Java가 다른 언어보다 느리다는 이야기가 많이 있습니다. 연산이 중요한 작업(CPU-Intensive)이라 C++로 짜는 것이 최선이거나, CPU레벨에서 제공하는 방법을 이용하면 최적화가 가능하지만 Java로 짜면 이용하지 못하는 작업들이 있습니다. 이런 작업들은 Java 같은 언어로 짜기에는 퍼포먼스가 너무 안나와서 문제가 됩니다. 이런 작업들은 Java가 아닌 C++같은 언어로 작성해야겠죠. 하지만 대부분의 비즈니스 로직은 Java로도 충분한 퍼포먼스를 낼 수 있습니다. 일반적인 경우에 Java가 다른 언어보다 느리다는 말은 아마 I/O와 Swing 때문이 클 것 입니다.
Java 프로그래머라면 Java API로 IO를 많이 다뤄보셨을겁니다. java.io 패키지의 클래스로서, byte배열의 입출력을 담당하는 OuputStream, InputStream 외에 문자타입 자료의 입출력을 담당하는 Wirter와 Reader가 그것입니다. 물론 데코레이터패턴으로 다양한 방법으로 이용할 수 있는 클래스들도 있죠.
몇 가지 예시를 살펴보죠.

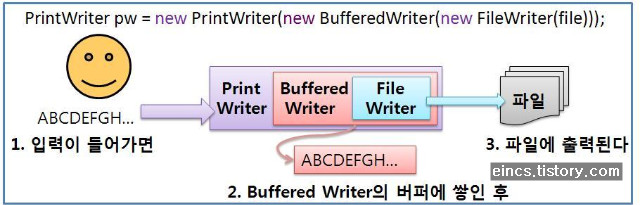
실제 모양새를 상당히 추상화 시켜놓긴 했습니만 이해하기는 쉬우실 겁니다.
어쨋든 위와 같이 File에 문자 기반 I/O를 사용하기 위해선 File path FileWriter나 FileReader를 만들고 추가 기능을 위해 PrintWirter, PrintReader등의 클래스, 버퍼기능을 추가하여 속도향상을 하기 위해선 Buffered라는 접두어가 붙은 클래스를 이용하면 되었습니다. 참으로 데코레이터패턴을 효과적으로 쓴 케이스라고 할 수 있겠네요. 덕분이 처음 배우는 사람도 그나지 어렵지 않게 사용 할 수 있었습니다.
하지만 이런 기존 Java I/O는 상당히 느리고 비효율적이라는 평가를 많이 받았습니다. 실제로 그럴수밖에 없는 이유를 살펴보면 크게 두 가지입니다. 첫 번째 이유는 OS에서 관리하는 커널 버퍼에 직접 접근할 수 없었던 것이고, Blocking I/O여서 매우 비효율적이었다는 것이 두 번째 이유입니다. 이에 대해 자세해 살펴 보도록 하죠.
1.1. 기존 자바 IO는 커널 버퍼를 직접 핸들링 할 수 없어서 느리다!
기존 자바 IO에서는 커널 버퍼를 직접 접근하는 소위 Direct Buffer를 핸들링 할 수가 없었습니다. 소켓이나 파일에서 Stream이 들어오면 커널 버퍼에 쓰여지게 되는데, Code상에서 이에 접근 할 수 있는 방법이 없었기 때문입니다. 따라서 JVM이 JVM 내부의 메모리에 불러온 후에야 이 데이터에 접근 할 수 있었는데 “커널에서 JVM내부 메모리로 복사한다”라는 오버헤드가 있었기 때문에 느렸던 거죠. JVM 내부의 메모리라고 하면 int, char변수의나 byte[] 등 자료형 이겠죠. int, char, long 같은 primitive type 은 당연히 JVM내부에서 프로세스별로 할당된 스택에 저장되겠고, 배열은 JVM 내부 힙 메모리에 저장되겠죠. 말로만 하면 어려우니 그림과 함께 설명하도록 하겠습니다.
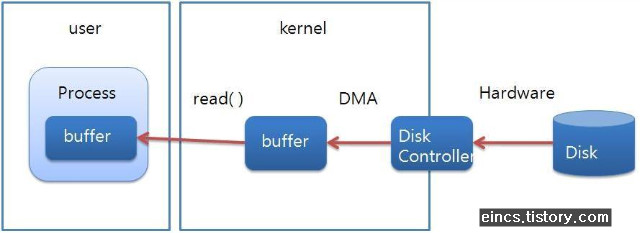
기존의 Java IO가 디스크에서 파일을 읽을 때의 과정은 다음과 같습니다.
- Process(JVM)이 file을 읽기 위해 kernel에 명령을 전달
- Kernel은 시스템 콜(read())을 사용하
- 디스크 컨트롤러가 물리적 디스크로 부터 파일을 읽어옴
- DMA를 이용하여 kernel 버퍼로 복사
- Process(JVM)내부 버퍼로 복사
따라서 다음 과 같은 문제점 이 생길 수 있죠.
- JVM 내부 버퍼로 복사할 때, CPU가 관여
- 복사 Buffer 활용 후 GC 대상이 됨
- 복사가 진행중인 동안 I/O요청한 Thread가 Blocking
위 와 같은 오버헤드가 생길 수 있습니다. 이에 대해 자세히 알아보도록 하겠습니다.
소중한 CPU 자원이 낭비되기 때문에 느리다.
CPU가 관여해버기리 때문에, 버퍼가 복사하는 것 자체가 리소스를 잡아먹게 됩니다. 큰 오버헤드죠. 물리적 디스크에서 커널영역으로 복사하는 것은 DMA의 도움으로 CPU가관여하지 않기 때문에, 오버헤드가 매우 적습니다. 따라서, 만약 CPU 자원을 사용하여 내부 버퍼로 복사하지 않고 직접 커널 버퍼를 사용한다면 중요한 CPU 자원을 다른 곳에 써서 더 효율적으로 프로그래밍이 가능하겠죠. 디스크나에서 커널버퍼에 복사하는 과정은 CPU가 관여하지 않고 DMA가 해줍니다. CPU가 관여하지 않는다는 것은 CPU의 자원을 다른 곳에 쓸 수 있다는 것을 의미하죠.
내부 버퍼로 사용한 메모리가 GC 대상이 되기 때문에 느리다.
그리고 기존 Java I/O에서 내부 버퍼로 사용한 데이터 변수 - 기본적으로는 배열이 되겠죠 - 가 GC의 대상이 됩니다. 일단 버퍼로 사용하고 난 후에는 필요가 없어지기 때문이죠. Java에서 GC는 오버헤드입니다. 물론 JVM에 나올 때마다 GC의 성능이 매우 좋아지고 있긴 합니다만여전히 C나 C++에 비해 오버헤드이기 때문에 코딩을 할 때 최대한 피해야 합니다.
마지막 Blocking에 관한 부분은 다음 절에서 이야기 해보도록 하겠습니다.
1.2. 기존 자바 IO는 Blocking IO 라서 느리다!
Thread에서 블로킹이 발생하기 때문에 느리다.
위의 그림에서, 복사해올 때, I/O 요청한 Process, 정확히는 Thread가 블로킹됩니다. OS에서는 디스크를 읽는 효율을 높이기 위해 파일에서 최대한 많은 양의 데이터를 커널 버퍼에 저장합니다. 따라서 기존 Java I/O 에서는 커널 버퍼에서 JVM 내부 버퍼로 복사하는 동안 다른 작업을 못하게 됩니다. 만약 또 커널 버퍼에 직접 접근 할 수 있다면 Thread가 복사하는 시간에 다른 작업을 할 수 있겠죠.
기존 Java I/O로는 끔찍하게 비효율적인 Server Program을 만든다.
Blocking 관련된 문제점은 이 뿐만이 아닙니다. 기존 Java I/O를 이용한 Server-Client Network 프로그램을 만들 때 더더욱 심각한 문제점을 야기합니다. 이에 대해선 간단한 예제와 함께 알아보도록 하죠.
ServerSocket server = new ServerSocket(10001);
System.out.println(“접속을 기다립니다.”);
while(true){
Socket sock = server.accept();
Service service = new Service (sock);
service.start();
serviceList.add(service);
}
일번적으로 Java에서 소켓 프로그래밍을 할 때, 위와 같이 Server를 작성하죠. 아래는 Service라는 클래스를 정의한 코드입니다.
class Service extends Thread {
private Socket socket = null;
private OuputStream out = null;
private InputStream in = null;
public Service(Socket socket)
{
this.socket = socket;
out = socket.getOutputStraem();
in = socket.getInputStream();
}
public run()
{
while(true) {
String request = in.read();
String response = processReq(request);
out.write(response);
}
}
}
기존의 Java로는 위와 같이 Server 프로그램을 작성했습니다. 위와 같이 작성하게되면 다음과 같은 특성이 있습니다.
- 클라이언트가 접속할 때마다 블로킹됩니다.
- 클라이언트 접속할 때마다 Thread가 생성됩니다.
이런 특성이 어떤 문제를 발생시키는지 알아보도록 하겠습니다.
기존 I/O의 Server는 블로킹 되므로 느리다.
클라이언트가 접속을 하게되면 새로운 Thread를 생성해야합니다. 자바에서 Thread를 생성하는건 c나 c++에 비하여 비교적 쉽지만 내부적으로는 매우 복잡한 프로세스를 가지고 있습니다. 따라서 Thread 생성하는 것은 비교적 시간이 오래 걸리는 오버헤드가 발생하는 작업입니다. 만약 한 클라이언트가 접속 후 짧은 시간 후에 다른 클라이언트가 Server에 접속을 시도한다면 Connection이 맺어지기 위해선 바로 앞서 접속한 클라이언트의 Thread가 모두 생성되기를 기다려야 합니다. 이렇게 waiting 해야 한다는 점에서 blocking I/O라고 볼 수가 있습니다.
이 뿐만 아니라 Service 클래스 내부에서 Socket resquest와 response를 사용할때도 blocking 됩니다. 이 점은 위에서도 언급했던 내용인데, socket에서 들어온 패킷을 읽기위해 read()함수를 호출하면 I/O를 요청 한 것이므로 해당 Thread가 블로킹 됩니다.
클라이언트 접속할 때마다 Thread가 생성됩니다.
클라이언트가 접속할 때마다 Thread가 생성되는데, 클라이언트가 접속 종료 후에는 Thread가 사용 중지가 되므로 GC대상이 됩니다. Client가 빈번히 접속하고 접속을 끊는 네트워크 환경에서 큰 문제가 될 수가 있겠죠. 앞서 말했듯이 GC는 Java에서 매우 큰 오버헤드입니다. 물론 ThreadPool을 사용한다면 Thread가 GC되는 것에 대한 오버헤드는 줄일 수 있습니다만 여전히 또 다른 문제가 발생합니다. ThreadPool은 Pool이라는 패턴입니다. Thread를 미리 N개를 생성해놓고 관리하고 있다가, Thread가 필요하게 되면 ThreadPool에서 하나를 꺼내 씁니다. 자원을 모두 사용하면 GC해버리는 것이 아니라 ThreadPool에 다 사용했음을 알리면 다음 번에 다시 꺼내 쓸 수 있습니다. Java의 장점이나 단점중 하나인 GC의 오베헤드를 줄이기 위한 방법 중 하나로 꽤 자주 쓰이는 패턴입니다.
만약 서버에 매우 많은 수의 클라이언트가 접속을 시도하게 된다면 그 만큼의 Thread가 필요하게 됩니다. 그만큼 서버의 자원이 낭비되는것이죠.
위와 같은 이유로 기존의 Java I/O는 C나 C++과 같이 직접 시스템 콜을 사용하여 입출력을 하는 언어보다 느립니다. 후에 또다시 간단히 설명하겠지만, C나 C++에서는 select()와 같은 시스템콜을 사용하기 때문에 서버 프로그램에서 클라이언트마다 Thread를 만들 필요가 없습니다. Java NIO에서는 select() 시스템콜을 간접적으로나마 사용할 수 있도록 지원해줘서 Thread가 많이 필요하지 않으면서도 좋은 성능을 내는 서버를 만들 수 있도록 기술을 제공하고 있습니다. 하지만 jdk1.3부터 새로 생긴 java.nio 패키지의 NIO가 기존 Java I/O의 문제점을 어떻게 해결했는지 알아보도록 하겠습니다.
2. NIO는 왜 기존 Java I/O 더 빠른가?
위에서 기존의 Java I/O의 단점 대해 살펴봤습니다. 위와 같은 문제점이 있는 Java I/O는 jdk 1.3에 와서야 그 단점을 보완하는 NIO가 등장하게 되었습니다. 시스템 서비스를 사용하지도 못하고 여기저기 헛점 투성이인 Java I/O 의 문제점이 jdk 1.3에서야 보완된 이유는 Java의 철학 때문 이겠죠. Java의 가장 중요한 특성인 플랫폼 간의 이식성, 다시말해 Once Write, Run AnyWay! 를 지키기 위해서 각 OS별로 system call이나 커널을 직접 이용하는 것은 기술적으로 매우 어려운 일이었습니다. jdk 1.3에서야 통일된 인터페이스로 각 시스템 별로 네이티브 언어를 이용하여 그 기능을 구현해주는 노가다가 완성된거죠. 여튼, 각설하고 NIO가 어떻게 Java I/O를 단점을 보완했는지에 대해서 간단히 알아보도록 하겠습니다. 자세한건 다음 포스팅에서 설명할 것이기 때문에 내용이 짧아 질 것 같군요^^
2.1. NIO는 Direct Buffer 로 커널 버퍼를 직접 핸들링하기 때문에 빠르다!
기존 Java I/O에서의 JVM 내부 메모리로의 복사문제를 해결하기 위해 NIO에서는 커널 버퍼에 직접 접근할 수 있는 클래스를 제공해줍니다. Buffer클래스들이 그것인데요, 내부적으로 커널버퍼를 직접 참조하고 있습니다. 일종의 포인터 버퍼라고 볼수있는데 운영체제가 제공해주는 효율적인 I/O 핸들링 서비스를 이용 할 수 있게 해줍니다. 따라서 위에서 발생한 복사문제로 인해 CPU자원의 비효율성, I/O 요청 Thread가 Blocking 되는 문제점 등이 해결될 수 있는 것이죠.
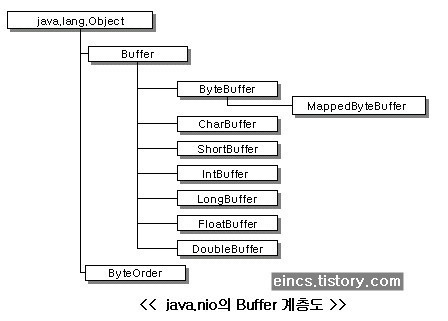
위 그림을 살펴보면 Buffer에는 여러가지 자료형을 지원합니다만, DirectBuffer는 [ByteBuffer][1]만 지원합니다. 따라서 커널 버퍼를 직접 사용하고 싶다면 불편하더라도 ByteBuffer만 사용해야합니다. Buffer를 만드는 방법은 다음과 같습니다.
ByteBuffer buf = ByteBuffer.allocate(10);
ByteBuffer directBuf = ByteBuffer.allocateDirect(10);
아랫줄의 코드와 같이 사용하여야 커널 버퍼를 직접 이용하는 것입니다. 윗 줄은 기존 방식과 같은 거죠. JVM내부에 메모리가 할당 됩니다.
Direct Allocate [ByteBuffer][1]의 put(), get(), position(), flip(), clear() 등의 메소드로 커널 버퍼를 핸들링 할 수 있습니다. 자세한건 다음 포스팅에서 알아보도록 하겠습니다.
이번 포스팅에서는
NIO에서는 커널 버퍼를 직접 이용할 수 있게 해주는 Buffer Class를 지원한다! 커널 버퍼를 직접 이용할수 있는건
ByteBuffer.directAllocate(SIZE);로 생생된 ByteBuffer뿐이며, 다른 Buffer들은 기존의 방식과 똑같다.
만 기억하시면 됩니다.
2.2. NIO에서 System Call을 간접적으로 사용가능하게 해주기 때문에 빠르다!
위 에서 살펴보았던 서버프로그램의 예제를 기억하시나요? 엄청난 수의 Thread가 생성되고 GC가 되어야 했죠. NIO에서는 이점을 해결 했습니다. c나 c++로 만들어진 Server Program은 Thread를 생성하지 않고도 많은 수의 클라이언트를 처리할 수 있습니다. 이를 가능케 해주는 것이 OS 레벨에서 지원하는 Scatter/Gather 기술과 Select() 시스템 콜입니다. Scatter/Gather은 시스템콜의 수를 줄이는 기술인데요, 덕분에 I/O를 빠르게 만들 수 있죠. c나 c++에서는 이런 OS수준의 기술들을 이용하여 I/O속도를 향상시켜왔지만 java에서는 이런 시스템에서 제공하는 기술을 사용할 수 있는 방법이 없었죠. 하지만 NIO에서는 가능합니다. 이런 것을 가능하게 해주는 Class가 바로 Channel과 Selector입니다.
