네이버 검색엔진이 이상하게 작동하는 것을 발견하였습니다. 제가 잘못생각한건지 네이버의 검색엔진이 이상한건지 잘 모르겠지만, 아무래도 네이버의 문제인 듯합니다. 혹시나 원인을 아시는 분은 알려주시기 바랍니다. 문제점이 무엇이냐를 말씀드리기 전에 검색엔진에 대해서 간략하게 설명하고 넘어가도록 하겠습니다.
1. 검색엔진의 간략적인 구조
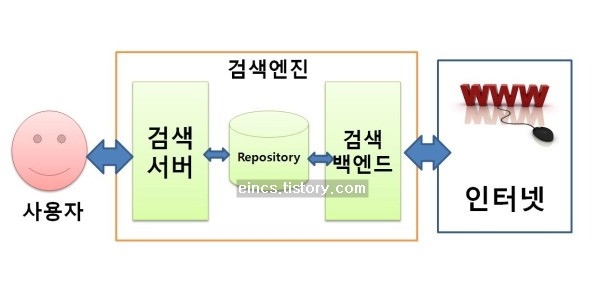
검색엔진은 크게 검색서버, 리포지토리(Repository), 검색벡엔드로 나뉩니다. 검색서버는 그야말로 사용자에게서 검색 쿼리를 전달받아 그 결과를 응답해주는 서버입니다. 리포지토리는 검색엔진이 수집한 웹페이지의 정보를 담고 있는 데이터베이스라고 말할 수 있죠. 그리고 웹을 서핑하면서 웹페이지를 수집하는 부분이 검색벡엔드입니다.
검색백엔드의 부분을 간략히 알아보면 크롤러가 있습니다. 이 크롤러는 웹을 돌아다니며 웹페이지를 수집하죠. 그래서 붙여진 이름이 크롤러입니다. 웹페이지를 긁어 모은다는 뜻이겠죠. 이렇게 긁어 모은 웹페이지는 리포지토리(Repository)에 저장됩니다. 검색엔진은 이렇게 저장된 리포지토리에 인덱싱되어있는 웹페이지를 빠르게 검색하여 사용자에게 응답을 주는 것입니다.
2. 웹페이지의 모든 단어가 같은 중요도를 갖는 것은 아니다!
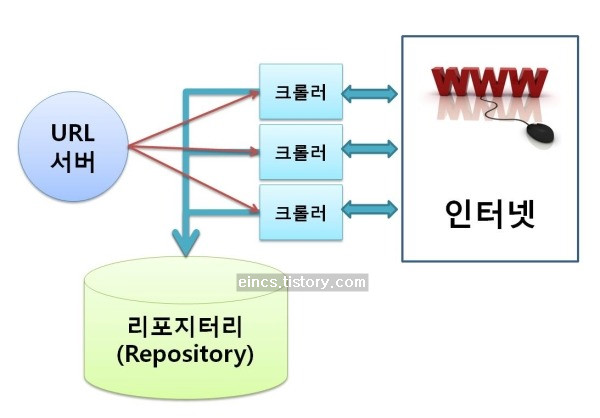
리포지토리에 크롤러가 수집한 웹페이지 정보를 저장할 때, 그냥 웹페이지 내용만을 넣는 것이 아닙니다. 위 그림처럼 각 페이지를 파싱하여 내용을 분해한 뒤, 그 속에서 단어를 추출하여 구조화하여 저장해 둡니다. 검색할 때마다 저장된 웹페이지를 읽어 파싱하여 결과를 만들어야 한다면 시간이 너무 오래 걸리고 검색 엔진 서버에도 상당히 부하를 주기 때문입니다. 이렇게 단어를 추출할 때 단순히 단어를 스캔하는 것이 아니라 html 문서의 구조에 따라 단어의 중요도를 다르게 둡니다.
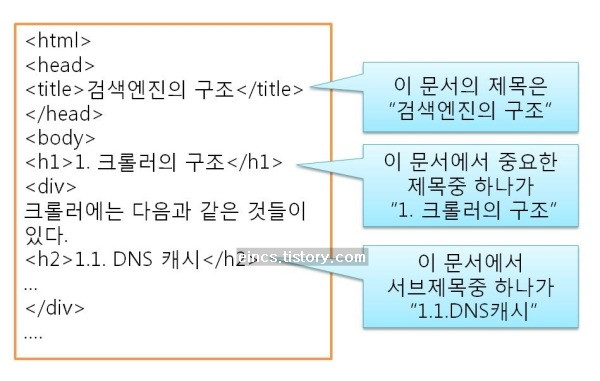
예를 들어보겠습니다. 같은 단어라도 그냥 문서에 포함된 것과 h1 태그 안에 있는 단어는 중요도가 다른 것으로 인식합니다. 그냥 본문에 있는 단어에 비해 제목에 있는 단어는 문서의 내용을 더 잘 나타내 주는 것으로 판단하는게 당연하기 때문입니다. 특히 title 안에 있는 내용은 웹페이지 자체의 제목이기 때문에 그 중요도는 매우 높습니다.
이런 HTML 문서 구조를 고려하여 검색엔진의 상위에 노출되도록 하는 기법을 “검색엔진 최적화 기법” 이라고 합니다. 노출되어야할, 중요한 단어는 최대한 title, h1, h2…태그에 넣도록 하고, 자신의 블로그 포스팅간에 거미줄 처럼 링크를 시켜두면 검색엔진 상위에 노출확률이 커지게 되는거죠. 그래서 전 항상 포스팅의 주제목외에 부제목을 쓸때에는 h2, h3 태그를 사용하고 있습니다.
- 같은 단어라도 HTML문서 구조에 따라 중요도가 다르다.
- title, h1 태그 안에 있는 단어가 중요도가 높다.
- 이를 이용한 상위 노출 기법을 “검색엔진 최적화 기법” 이라한다.
여러분들의 블로그에도 “검색엔진 최적화 기법”을 적용해 보세요.
3. 네이버는 title 태그를 무시하나요?
최근에 Java NIO에 관련된 포스팅을 여러개 하였습니다. 물론 검색엔진을 통해 유입되는 분들이 많았습니다. 유입 키워드와 유입 경로를 확인하던차 네이버를 통해 들어오신 분들이 많아 한번 들어가 봤습니다. 그런데 아래 그림과 같이 웹페이지의 제목이 ## 태그 안에 지정한 서브 제목으로 되어 있더랍니다. 그 중 한 포스팅을 보시면 아시겠지만,
<h3>1.1. ByteBuffer의 사용 방법!</h3>
처럼 작성되어 있는 것을 아실 수 있을 겁니다.
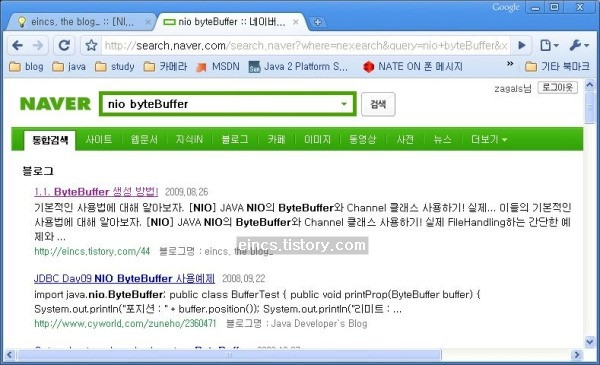
네이버는 h3 태그 제목을 웹페이지 제목으로 인식하나요? h1 태그도 아니라 서브제목의 서브제목인 h3 태그를 말이죠. 혹시나 해서 구글도 검색해보았습니다.
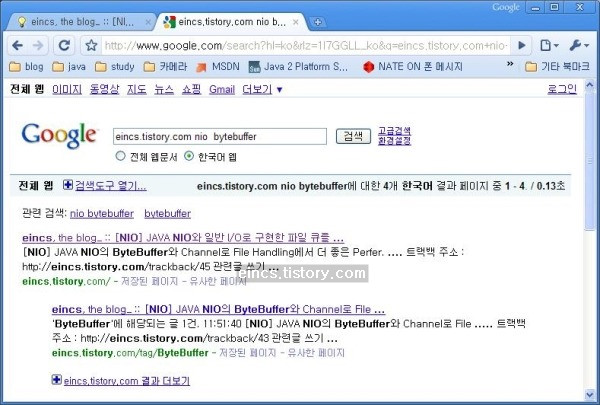
구글에선 title 안의 제목을 웹페이지 제목으로 제대로 인식하는 걸로 보입니다. 네이버…뭔가 이상합니다.
h1 태그를 사이트 제목으로 쓴는것이 관례라는 東氣號太님의 덧글을 보고 찾아보았는데, H1 태그는 한번만 써야 되는지에 대한 고찰을 다룬 포스트를 찾을 수 있었습니다. 포스트의 내용을 보면 h1태그를 사이트 제목으로 쓰면서 한번만 써야되는지는 결국 개발자의 마음대로 라고 결론을 짓고 있는것으로 보이는데, 포스트 내용이나 달린 댓글의 내용을 보면 실제로 많은 사이트에서,
<h1 class="logo">사이트제목</h1>
와 같은 형식으로 페이지의 제목을 표현하는 것이 관례가 되어 있다는 것을 알게되었네요. 아무래도 검색엔진이라면 관례를 따르겠죠. 이게 맞는것 같습니다. 저도 h1은 최대한 한번망 사용하도록 고쳐야겠네요. 지금은 본문에 h1를 남발하고 있거든요.
일단 기본적으로 적용되어 있는 제 블로그의 글들의 구조는 다음과 같았습니다.
<div class=”titleWrap”>
<h1> 타이틀 </h1>
</div>
<div class=”article”>
<h1> 1. 제목 </h1>
<div> 내용 </div>
<h2> 1.1. 소제목 </h2>
<div> 내용 </div>
<h3> 1.1.1. 좀 더 작은 소제목</h3>
<div> 내용 </div>
<h3> 1.1.2. 좀 더 작은 소제목</h3>
<div> 내용 </div>
<h2> 2.1. 소제목 </h2>
<div> 내용 </div>
<h3> 2.1.1. 좀 더 작은 소제목</h3>
<div> 내용 </div>
<h3> 2.1.2. 좀 더 작은 소제목</h3>
<div> 내용 </div>
<h1> 2. 제목 </h1>
<div> 내용 </div>
</div>
위 구조에서 네이버에서 제목으로 가져간 부분은
<h2>1.1. 소제목 </h2>
라고 볼 수 있습니다. 네이버에서 가정한 것은 다음과 같다고 생각합니다.
- h1은 블로그 타이틀로 쓰인다고 가정. (관례적으로)
- h2는 당연히 글 제목으로 가정. (관례적으로)
- 블로그는 title보다 글 제목으로 검색되는게 더 좋다고 가정.
- 네이버 검색엔진은 블로그를 크롤링 할 때는 h2 태그를 글 제목으로 인식.
따라서, 네이버 검색엔진에서는 h2부분을 블로글에 게시된 글 제목으로 판단한 것으로 보입니다.
생각해보면 일반적으로 페이지 제목은 title에 들어가는게 맞죠. 그런데 검색시 title보다는 글의 제목만 나타나면 더 좋겠죠. 왜냐면 title에는 쓸데없이 “블로그 이름 + 글 제목” 이 들어가는 경우가 대부분이니까요. 그래서 네이버 검색엔진은 글 제목만 따오는 방법으로 h2을 참조하는 방법을 사용한 듯 합니다. 따라서 네이버는 일반적인 관례에 따라 네이버는 많은 블로그에서 사용하는 관례에 특화된 HTML문서 해독 방법을 사용한 것이라고 말씀드릴 수 있겠네요.
- 관례를 따르도록 합시다.
- h1 태그에는 블로그 제목을 쓰도록 합시다. h1은 한번만 사용합니다.
- h2 태그에는 글의 제목을 쓰도록 합시다.
- 본문에는 h3, h4, h5, h6 태그만 사용하도록 합시다.
- 스타일은 css파일에 넣어 사용합니다.
역시 머리가 나쁘면 고생을 하는군요. 이런 관례에 대해 접할 수 있는 기회가 없었습니다. 하지만, 아무리 생각해도 검색엔진에서는 title태그에서 페이지 제목을 가져가는게 맞다고 생각합니다. 하지만 관례가 있다면 그것을 따르는 것도 맞다고 생각합니다. 하지만 네이버 검색엔진은 이런 관례를 지나치게 가정하고, 시스템에 적용하는게 아닌가 하는 것이 제 개인적인 생각입니다. 관례는 지켜 마땅하지만, 검색엔진에서도 이런 관례를 기정 사실로 가정하는건 너무하지 않나 싶습니다. 검색엔진은 거의 모든 웹페이지에 대해 범용적으로 적용되야 마땅하다고 생각하기 때문입니다.
